This resolves a particular issue with parsing YAML multiline, for
example:
```yaml
a: |
multiline literal
line 2
```
The regex used would capture the amount of indentation in the third
capture group and then use that as a kind of "status" to know which
lines are part of the indented multiline. However, because its a
captured group it has to be assigned a token which was `TextWhitespace`.
This meant that the indentation was outputted after the multiline,
technically it should be seen as an non-captured group, but then its no
longer to refer to it in the regex. Therefore I've gone with the
solution to add a new token, Ignore, which will not be emitted as a
token in the iterator, which can safely be used to make use of capture
groups but not have them show up in the output.
## Before
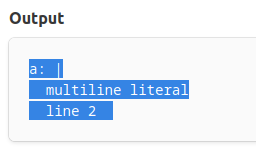
## After

This cleans up the API in general, removing a bunch of deprecated stuff,
cleaning up circular imports, etc.
But the biggest change is switching to an optional XML format for the
regex lexer.
Having lexers defined only in Go is not ideal for a couple of reasons.
Firstly, it impedes a significant portion of contributors who use Chroma
in Hugo, but don't know Go. Secondly, it bloats the binary size of any
project that imports Chroma.
Why XML? YAML is an abomination and JSON is not human editable. XML
also compresses very well (eg. Go template lexer XML compresses from
3239 bytes to 718).
Why a new syntax format? All major existing formats rely on the
Oniguruma regex engine, which is extremely complex and for which there
is no Go port.
Why not earlier? Prior to the existence of fs.FS this was not a viable
option.
Benchmarks:
$ hyperfine --warmup 3 \
'./chroma.master --version' \
'./chroma.xml-pre-opt --version' \
'./chroma.xml --version'
Benchmark 1: ./chroma.master --version
Time (mean ± σ): 5.3 ms ± 0.5 ms [User: 3.6 ms, System: 1.4 ms]
Range (min … max): 4.2 ms … 6.6 ms 233 runs
Benchmark 2: ./chroma.xml-pre-opt --version
Time (mean ± σ): 50.6 ms ± 0.5 ms [User: 52.4 ms, System: 3.6 ms]
Range (min … max): 49.2 ms … 51.5 ms 51 runs
Benchmark 3: ./chroma.xml --version
Time (mean ± σ): 6.9 ms ± 1.1 ms [User: 5.1 ms, System: 1.5 ms]
Range (min … max): 5.7 ms … 19.9 ms 196 runs
Summary
'./chroma.master --version' ran
1.30 ± 0.23 times faster than './chroma.xml --version'
9.56 ± 0.83 times faster than './chroma.xml-pre-opt --version'
A slight increase in init time, but I think this is okay given the
increase in flexibility.
And binary size difference:
$ du -h lexers.test*
$ du -sh chroma* 951371ms
8.8M chroma.master
7.8M chroma.xml
7.8M chroma.xml-pre-opt
Benchmarks:
$ hyperfine --warmup 3 \
'./chroma.master --version' \
'./chroma.xml-pre-opt --version' \
'./chroma.xml --version'
Benchmark 1: ./chroma.master --version
Time (mean ± σ): 5.3 ms ± 0.5 ms [User: 3.6 ms, System: 1.4 ms]
Range (min … max): 4.2 ms … 6.6 ms 233 runs
Benchmark 2: ./chroma.xml-pre-opt --version
Time (mean ± σ): 50.6 ms ± 0.5 ms [User: 52.4 ms, System: 3.6 ms]
Range (min … max): 49.2 ms … 51.5 ms 51 runs
Benchmark 3: ./chroma.xml --version
Time (mean ± σ): 6.9 ms ± 1.1 ms [User: 5.1 ms, System: 1.5 ms]
Range (min … max): 5.7 ms … 19.9 ms 196 runs
Summary
'./chroma.master --version' ran
1.30 ± 0.23 times faster than './chroma.xml --version'
9.56 ± 0.83 times faster than './chroma.xml-pre-opt --version'
Incompatible changes:
- (*RegexLexer).SetAnalyser: changed from func(func(text string) float32) *RegexLexer to func(func(text string) float32) Lexer
- (*TokenType).UnmarshalJSON: removed
- Lexer.AnalyseText: added
- Lexer.SetAnalyser: added
- Lexer.SetRegistry: added
- MustNewLazyLexer: removed
- MustNewLexer: changed from func(*Config, Rules) *RegexLexer to func(*Config, func() Rules) *RegexLexer
- Mutators: changed from func(...Mutator) MutatorFunc to func(...Mutator) Mutator
- NewLazyLexer: removed
- NewLexer: changed from func(*Config, Rules) (*RegexLexer, error) to func(*Config, func() Rules) (*RegexLexer, error)
- Pop: changed from func(int) MutatorFunc to func(int) Mutator
- Push: changed from func(...string) MutatorFunc to func(...string) Mutator
- TokenType.MarshalJSON: removed
- Using: changed from func(Lexer) Emitter to func(string) Emitter
- UsingByGroup: changed from func(func(string) Lexer, int, int, ...Emitter) Emitter to func(int, int, ...Emitter) Emitter
For named groups that are not given, an Error will be emitted anyway.
This also handles the case when an Emitter for group `0` is provided
or not. Since numbers can also be used for names.
But it might be over-doing, because why would anyone use ByGroupNames
if they wanted to assign a token to the whole match?!
The engine was always passing a string sliced to the current position,
resulting in ^ always matching. Switched to use
FindRunesMatchStartingAt.
Fixes#242.