fix#744
related issue: go-gitea/gitea#32136
current markdown lexer is tokenizing by whitespace, but in markdown
sytanx this implementation can cause some errors.
No open issue, but I wanted this for myself so I figured I'd open a PR
as well. 🙂
I've used the third example from the jsonnet site as the test:
https://jsonnet.org/
Converted uses the pygments converter, and here's a quick screenshot of
the playground:

It seems to have a small problem with strings as keys, but otherwise
looks close.
Signed-off-by: jolheiser <git@jolheiser.com>
https://github.com/alecthomas/chroma/issues/425 shows that generics are
not correctly identified in general, but they are rather being treated
as JSX elements. I proposed a simple solution in the comments by adding
a space between `<` and the word next to it, but I believe most people
will either not find the solution or some of them will find it rather
unappealing.
For this reason, I made the JSX rules recursive and added a `","`
`Punctuation` token inside so that there can be a number of generics
used, as well as allowing nested generics. While I am not really fond of
this hack, given that generics are already treated as JSX elements, I
think this is a fair and easy enough solution for most cases.
#### Before
<img width="359" alt="Screenshot 2024-09-20 at 9 28 05 PM"
src="https://github.com/user-attachments/assets/b03c2c8a-3278-438b-8803-00eb62cc4a17">
#### With spacing solution
<img width="392" alt="Screenshot 2024-09-20 at 9 30 13 PM"
src="https://github.com/user-attachments/assets/89289476-c92a-41df-b893-5ab289fa96aa">
#### With recursive JSX and `","` `Punctuation` token
<img width="362" alt="Screenshot 2024-09-20 at 9 55 11 PM"
src="https://github.com/user-attachments/assets/d77d892e-667d-4fb4-93cf-8227d5bd4b17">
This adds #994 Beeflang.
The syntax itself is just a modifed version of c# with a few keywords
added or removed.
Also Ive added a test and run the test until it worked.
I am unsure if the mime_type is relevant to keep in there since I dont
know where that actually used.
Another thing im unsure of is how the selection of what language/syntax
to use for a file actually works aka:
Does this actually choose Beef syntax highlighting over Brainfuck if its
used on a beef (.bf) file ?
for that I would probably need help.
Co-authored-by: Booklordofthedings <Booklordofthedings@tutanota.com>
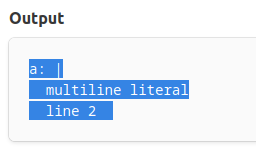
This resolves a particular issue with parsing YAML multiline, for
example:
```yaml
a: |
multiline literal
line 2
```
The regex used would capture the amount of indentation in the third
capture group and then use that as a kind of "status" to know which
lines are part of the indented multiline. However, because its a
captured group it has to be assigned a token which was `TextWhitespace`.
This meant that the indentation was outputted after the multiline,
technically it should be seen as an non-captured group, but then its no
longer to refer to it in the regex. Therefore I've gone with the
solution to add a new token, Ignore, which will not be emitted as a
token in the iterator, which can safely be used to make use of capture
groups but not have them show up in the output.
## Before
## After

Ported lexers for mcfuntion, snbt from Pygments using
`pygments2chroma_xml.py` script.
While doing so, I encountered lack of `LiteralNumberByte` in TokenType,
so I've added the type and regenerated tokentype_enumer.go.
This PR changes `CommentSingle` to not consume the newline at the end as
a part of comment.
That solves the problems of single line comment being not parsed at the
end of the line or at the end of the file. Which was reported earlier as
the reason to not highlight single line comment properly.
Disabling `EnsureNL: true` does not add unnecessary newline element for
`Text`, `CommentSymbol` symbols. Using chroma in console with syntax
highlighting was unusable becasue of this, since typing e.g. `b := `
adds newline each time space is at the end when host app asks for
highlighted text from `quick`.
Tokens behavior:
<table>
<tr>
<td> Before </td> <td> After </td>
</tr>
<tr>
<td>
``` go
t.Run("Single space", func(t *testing.T) {
tokens, _ := chroma.Tokenise(Go, nil, " ")
expected := []chroma.Token{
{chroma.Text, " \n"},
}
assert.Equal(t, expected, tokens)
})
t.Run("Assignment unfinished", func(t *testing.T) {
tokens, _ := chroma.Tokenise(Go, nil, "i = ")
expected := []chroma.Token{
{ chroma.NameOther, "i" },
{ chroma.Text, " " },
{ chroma.Punctuation, "=" },
{ chroma.Text, " \n" },
}
assert.Equal(t, expected, tokens)
})
t.Run("Single comment", func(t *testing.T) {
tokens, _ := chroma.Tokenise(Go, nil, "// W")
expected := []chroma.Token{
{ chroma.CommentSingle, "// W\n" },
}
assert.Equal(t, expected, tokens)
})
```
</td>
<td>
``` go
t.Run("Single space", func(t *testing.T) {
tokens, _ := chroma.Tokenise(Go, nil, " ")
expected := []chroma.Token{
{chroma.Text, " "},
}
assert.Equal(t, expected, tokens)
})
t.Run("Assignment unfinished", func(t *testing.T) {
tokens, _ := chroma.Tokenise(Go, nil, "i = ")
expected := []chroma.Token{
{ chroma.NameOther, "i" },
{ chroma.Text, " " },
{ chroma.Punctuation, "=" },
{ chroma.Text, " " },
}
assert.Equal(t, expected, tokens)
})
t.Run("Single comment", func(t *testing.T) {
tokens, _ := chroma.Tokenise(Go, nil, "// W")
expected := []chroma.Token{
{ chroma.CommentSingle, "// W" },
}
assert.Equal(t, expected, tokens)
})
```
</td>
</tr>
</table>
This introduces some additional keywords. I've also scripted this on our
end hence the changes in formatting and encoding of certain characters
in attribute values.
This also includes:
- Some tests
- Updates to the README to call out the `--csrf-key` argument for
chromad. Without it securecookie throws an error.
New functions added to 3.12.0 (`PARSE_COLLECTION()`, `PARSE_KEY()`,
`RANDOM()`, `REPEAT()`, `TO_CHAR()`) and the current stand for the
upcoming 3.12.1 (`ENTRIES()`).
Some functions were also removed (`CALL_GREENSPUN()`, `PREGEL_RESULT()`)
but I think it makes sense to keep them in the definition so that
highlighting older queries still works.
Currently the following CUE results in the chroma lexer producing an
error token for the '@':
value: string @go(Value)
This code is, however, valid CUE. '@go' is an attributes.
This change adds lexer support for attributes in CUE.
https://bazel.build/concepts/build-ref
"such a boundary marker file could be MODULE.bazel, REPO.bazel, or in
legacy contexts, WORKSPACE or WORKSPACE.bazel."
'$' is valid in a bare field name in CUE. It is not special. It happens
to be used by convention at the start of field names, but that is about
it.
Definitions start with '#'.
Add a "section" of tests that cover the various types of field. There
are no errors in new "tests", whereas before (i.e. without the change to
the CUE lexer) there would have been.
With the introduction of generics,
tilde is a valid punctuation token in Go programs.
https://go.dev/ref/spec#Operators_and_punctuation
This updates the punctuation regex for the Go lexer,
and adds a test to ensure that it's treated as such.
* chore(deps): update all non-major dependencies
* fix: fixes for test and lint
Test was slow because we were deep-comparing lexers. This is
unnecessary as we can just shallow compare.
---------
Co-authored-by: renovate[bot] <29139614+renovate[bot]@users.noreply.github.com>
Co-authored-by: Alec Thomas <alec@swapoff.org>
* added: another rule for objectpascal lexer
* updated: objectpascal lexer testdata
* fixed: processing of control (escape) characters
* updated: test data for objectpascal lexer