Current tests still pass if `len` is implemented to calculate the height
of the tree (i.e. max(left.len(), right.len()) + 1 for each node). It
seems this is quite a common misunderstanding when doing this course.
With the new assert height implementation will fail, which hints towards
implementing `len` as a total number of nodes.
The content slides all use `fn main`, with the exception of the testing
segment. But with this change, where it makes sense exercises use tests
instead, and not both tests and `fn main`.
A small change in `book.js` supports running tests when a code sample
does not have `fn main` but does have `#[test]`, so these work
naturally.
Fixes#1581.
I suppose my `svgbob` skills leave a bit to be desired, but I think the
meaning is clear:
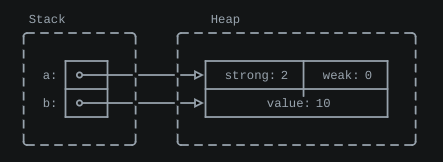
Now that I look through the `Rc` implementation, there's a weak count
for every strong count, so the `weak: 0` here is inaccurate. But, maybe
this is too much of an implementation detail? Should I just concentrate
on strong refs? I suppose I could put a `...` in that upper-right box,
to suggest there's more going on here?
Niche optimization is currently mentioned in three places:
- Enums (User-Defined Types, Day 1 Afternoon)
- Option (Standard Library Types, Day 2 Afternoon)
- Box (Smart Pointers, Day 3 Morning)
This is a tricky thing to get right, and it was just in the speaker
notes in each place. #1820 will introduce a fuller explanation.
Fixes#1820.
In #2153 I aimed to fix a link but broke it.
In this PR, I fix it and add
[`mdbook-linkcheck`](https://github.com/Michael-F-Bryan/mdbook-linkcheck)
to avoid future cases.
Some past fixes that could have been prevented, in addition to mine in
this PR:
* #811
* #2064
* #2146
Note:
`mdbook-linkcheck` may also check external links with a configuration
change.
It can be beneficial to check also external links from time to time. I
ran it here and found 3 broken links.
Maintainers - sorry for the lack of a preceding issue. We can discuss it
here.
Some remaining work is to fix the outdated internal links in the
translations, not done here.
Let me know what you think about the proposed contribution.
This PR completes #1502.
I've been thinking it'd be simpler to introduce `dyn Trait` via `&dyn
Trait` rather than waiting for the smart pointers section and `Box<dyn
Trait>`. This PR adds a slide to the Generics section that introduces
`&dyn Trait` and compares it to `&impl Trait`, juxtaposing
monomorphization and static dispatch against type-erasure and dynamic
dispatch. I've then updated the existing trait object slide to call back
to the earlier introduction, and call out that using `Box<dyn Trait>`
gives you an owned trait object rather than a borrowed one.
Give students a little more context for the binary tree exercise by
giving them the wrapper methods on `BinaryTree` at the start and
explicitly asking them to implement the methods on `Subtree`. I think
this simplifies the exercise a bit and makes it a bit more focused for
students.
This diagram is misleading and I often explain that the character data
of string literals resides in the executable's static data, with vtables
working the same.
This is a typo, that actually @mgeisler stopped in my previous PR, I was
just not around to fix it fast enough to make it to the previous merge.
Thanks for the catch!
The first change is to reformulate the English in a way, that
emphasizes, that this is not a decision of the compiler, but the
impossibility of computing an infinite value (e.g. changed the language
from "not compute" to "would not be able to compute").
The second change is to fix the error message, of course the error
message from the compiler is "recursive withOUT indirection", as
"recursive with indirection" is actually what we want.
Based on feedback from @marshallpierce that mornings took about 2.5
hours, this adjusts a bunch of the morning times downward to try to
match that. In other words, this is trying to make the times in the
course more accurate, rather than reducing the amount of time available
for these slides.
This also updates the `course-schedule` tool to be able to show
per-segment timings.
This is the result of running `dprint fmt` after removing `src/` from
the list of excluded directories.
This also reformats the Rust code: we might want to tweak this a bit in
the future since some of the changes removes the hand-formatting. Of
course, this formatting can be seen as a mis-feature, so maybe this is
good overall.
Thanks to mdbook-i18n-helpers 0.2, the POT file is nearly unchanged
after this, meaning that all existing translations remain valid! A few
messages were changed because of stray whitespace characters:
msgid ""
"Slices always borrow from another object. In this example, `a` has to remain "
-"'alive' (in scope) for at least as long as our slice. "
+"'alive' (in scope) for at least as long as our slice."
msgstr ""
The formatting is enforced in CI and we will have to see how annoying
this is in practice for the many contributors. If it becomes annoying,
we should look into fixing dprint/check#11 so that `dprint` can annotate
the lines that need fixing directly, then I think we can consider more
strict formatting checks.
I added more customization to `rustfmt.toml`. This is to better emulate
the dense style used in the course:
- `max_width = 85` allows lines to take up the full width available in
our code blocks (when taking margins and the line numbers into account).
- `wrap_comments = true` ensures that we don't show very long comments
in the code examples. I edited some comments to shorten them and avoid
unnecessary line breaks — please trim other unnecessarily long comments
when you see them! Remember we're writing code for slides 😄
- `use_small_heuristics = "Max"` allows for things like struct literals
and if-statements to take up the full line width configured above.
The formatting settings apply to all our Rust code right now — I think
we could improve this with https://github.com/dprint/dprint/issues/711
which lets us add per-directory `dprint` configuration files. However,
the `inherit: true` setting is not yet implemented (as far as I can
tell), so a nested configuration file will have to copy most or all of
the top-level file.
Currently, `BinaryTree::has` takes its argument by value. This is a
pretty unrealistic API for a Rust library. Let's fix this and take the
argument by reference instead.
Currently, the implementation uses if-then-else chains and `<` and `>`.
This is not the most idiomatic Rust. Instead, we can use `cmp` and
`match` to make the code easier to read.
---------
Co-authored-by: Dustin J. Mitchell <djmitche@google.com>
People are often confused by this: the fact that we can remove the `*`
in the `println!()` is not because the compiler auto-derefs here (it
does not), but because `Display` is implemented for `&T where T:
Display` (a blanket implementation).
I've taken some work by @fw-immunant and others on the new organization
of the course and condensed it into a form amenable to a text editor and
some computational analysis. You can see the inputs in `course.py` but
the interesting bits are the output: `outline.md` and `slides.md`.
The idea is to break the course into more, smaller segments with
exercises at the ends and breaks in between. So `outline.md` lists the
segments, their duration, and sums those durations up per-day. It shows
we're about an hour too long right now! There are more details of the
segments in `slides.md`, or you can see mostly the same stuff in
`course.py`.
This now contains all of the content from the v1 course, ensuring both
that we've covered everything and that we'll have somewhere to redirect
every page.
Fixes#1082.
Fixes#1465.
---------
Co-authored-by: Nicole LeGare <dlegare.1001@gmail.com>
Co-authored-by: Martin Geisler <mgeisler@google.com>