react-native-vosk - React ASR (Automated Speech Recognition)
NOTE: For some reason this module doesn't work (events are not being fired), so for now we use the actual react-native-vosk module, but with a patch
Joplin fork of react-native-vosk@0.1.12 with the following changes:
- The
onResult()event doesn't automatically stop the recorder - because we need it to keep running so that it captures the whole text. The original package was designed to record one keyword, but we need whole sentences. - Added the
stopOnly()method. This is because the originalstop()method wouldn't just stop, but clear everything, this preventing the usefulonFinalResult()event from event from being emitted. And we need this event to get the final text. - Also added
cleanup()method. It should be called once theonFinalResult()event has been received, and does the same as the originalstop()method. - The folder in
ios/Vosk/vosk-model-spk-0.4was deleted because unclear what it's for, and we don't build the iOS version anyway. If it's ever needed it can be restored from the original repo: https://github.com/riderodd/react-native-vosk
Speech recognition module for react native using Vosk library
Installation
Library
npm install -S react-native-vosk
Models
Vosk uses prebuilt models to perform speech recognition offline. You have to download the model(s) that you need on Vosk official website Avoid using too heavy models, because the computation time required to load them into your app could lead to bad user experience. Then, unzip the model in your app folder. If you just need to use the iOS version, put the model folder wherever you want, and import it as described below. If you need both iOS and Android to work, you can avoid to copy the model twice for both projects by importing the model from the Android assets folder in XCode. Just do as follow:
Android
In Android Studio, open the project manager, right-click on your project folder and New > Folder > Assets folder.
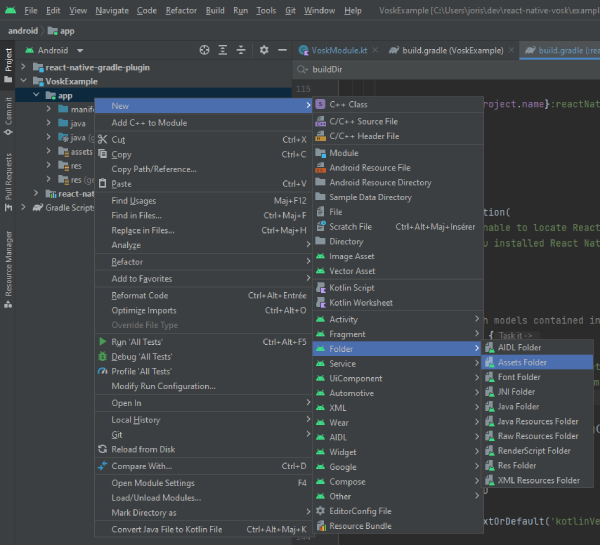
Then put the model folder inside the assets folder created. In your file tree it should be located in android\app\src\main\assets. So, if you downloaded the french model named model-fr-fr, you should access the model by going to android\app\src\main\assets\model-fr-fr. In Android studio, your project structure should be like that:
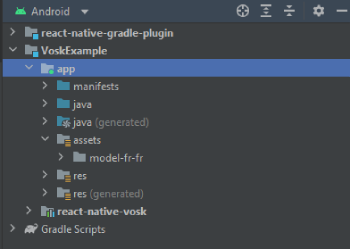
You can import as many models as you want.
iOS
In order to let the project work, you're going to need the iOS library. Mail contact@alphacephei.com to get the libraries. You're going to have a libvosk.xcframework file (or folder for not mac users), just copy it in the ios folder of the module (node_modules/react-native-vosk/ios/libvosk.xcframework). Then run in your root project:
npm run pods
In XCode, right-click on your project folder, and click on "Add files to [your project name]".
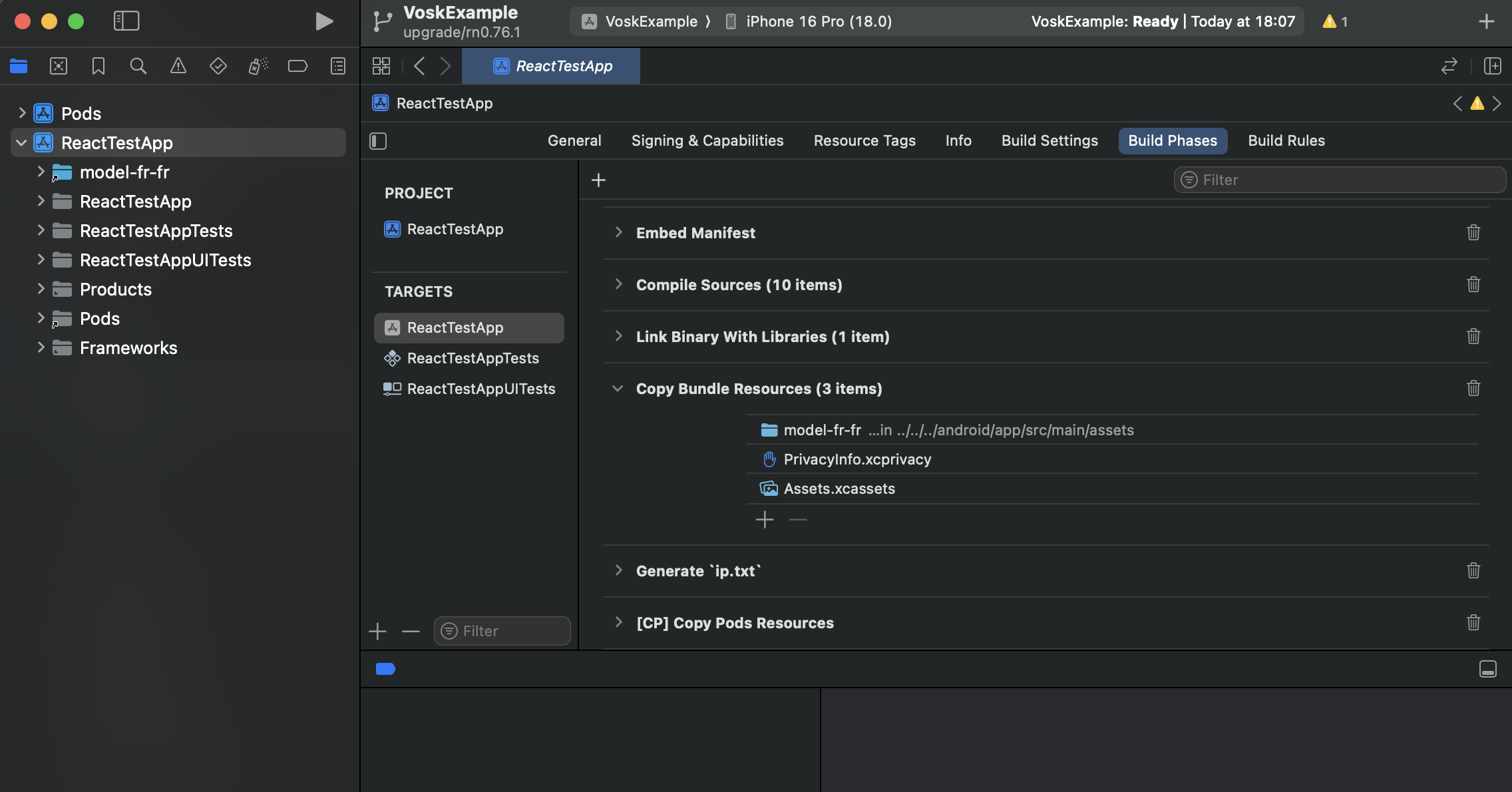
Then navigate to your model folder. You can navigate to your Android assets folder as mentionned before, and chose your model here. It will avoid to have the model copied twice in your project. If you don't use the Android build, you can just put the model wherever you want, and select it.
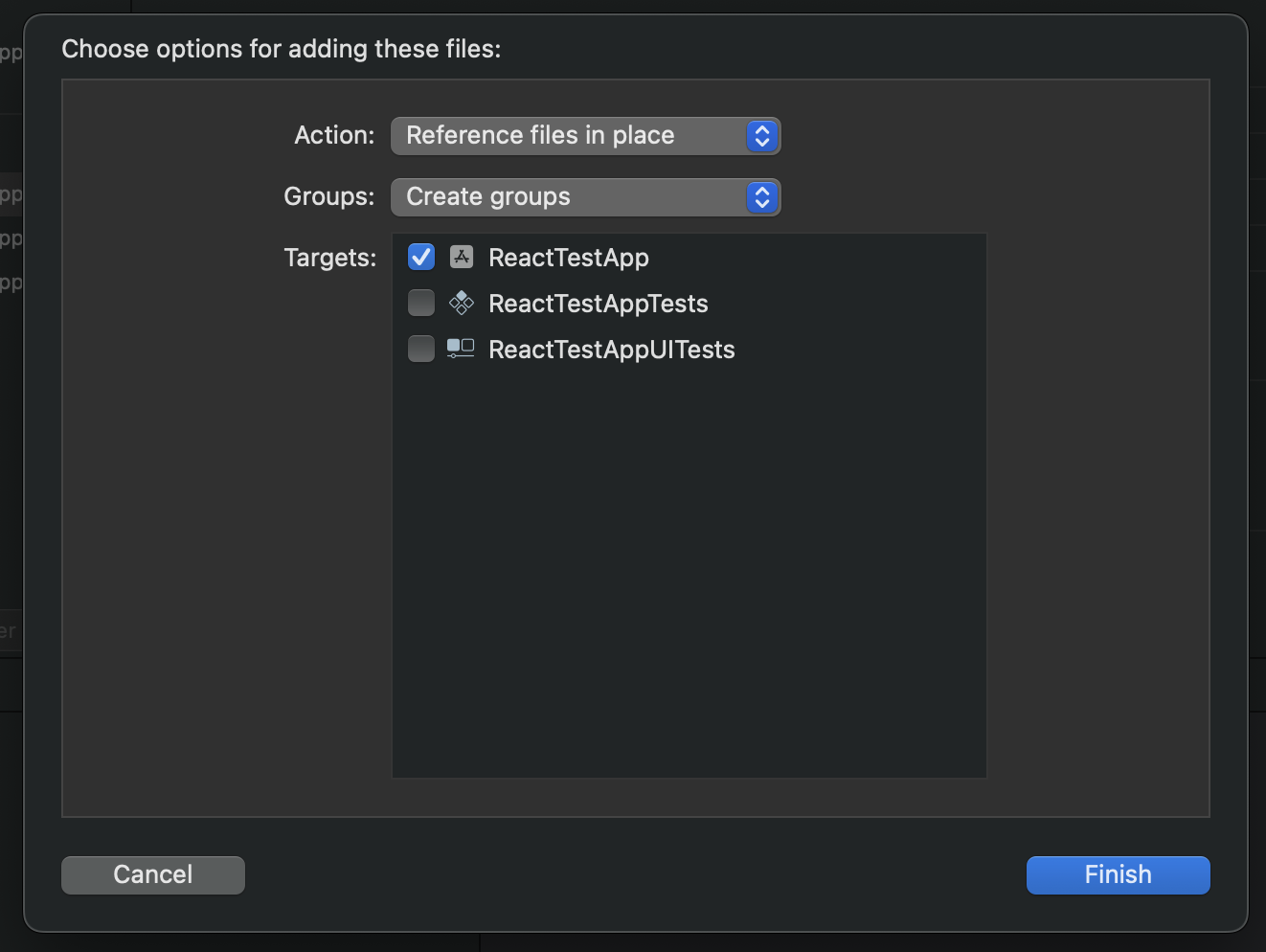
That's all. The model folder should appear in your project. When you click on it, your project target should be checked (see below).
Usage
import VoiceRecognition from 'react-native-voice-recognition';
// ...
const voiceRecognition = new VoiceRecognition();
voiceRecognition.loadModel('model-fr-fr').then(() => {
// we can use promise...
voiceRecognition
.start()
.then((res: any) => {
console.log('Result is: ' + res);
})
// ... or events
const resultEvent = vosk.onResult((res) => {
console.log('A onResult event has been caught: ' + res.data);
});
// Don't forget to call resultEvent.remove(); when needed
}).catch(e => {
console.error(e);
})
Note that start() method will ask for audio record permission.
Methods
| Method | Argument | Return | Description |
|---|---|---|---|
loadModel |
path: string |
Promise |
Loads the voice model used for recognition, it is required before using start method |
start |
grammar: string[] or none |
Promise |
Starts the voice recognition and returns the recognized text as a promised string, you can recognize specific words using the grammar argument (ex: ["left", "right"]) according to kaldi's documentation |
stop |
none |
none |
Stops the recognition |
Events
| Method | Promise return | Description |
|---|---|---|
onResult |
The recognized word as a string |
Triggers on voice recognition result |
onFinalResult |
The recognized word as a string |
Triggers if stopped using stop() method |
onError |
The error that occured as a string or exception |
Triggers if an error occured |
onTimeout |
"timeout" string |
Triggers on timeout |
Example
const resultEvent = voiceRecognition.onResult((res) => {
console.log('A onResult event has been caught: ' + res.data);
});
resultEvent.remove();
Don't forget to remove the event listener once you don't need it anymore.
Contributing
See the contributing guide to learn how to contribute to the repository and the development workflow.
License
MIT