The range parameters need to be set up before calling
sws_init_context (which selects which fastpaths can be used;
this gets called by sws_getContext); solely passing them via
sws_setColorspaceDetails isn't enough.
This fixes producing full range YUV range output when doing
YUV->YUV conversions between different YUV color spaces.
Signed-off-by: Martin Storsjö <martin@martin.st>
The IMF demuxer does not set the DTS and PTS of packets accurately in all
scenarios. Moreover, audio packets are not trimmed when they exceed the
duration of the underlying resource.
imf-cpl-with-repeat FATE ref file is regenerated.
Addresses https://trac.ffmpeg.org/ticket/9611
The sample mpeg4/mpeg4_sstp_dpcm.m4v existed in the FATE-suite,
but it was surprisingly unused.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
This long-existing feature calculates subtitle durations by keeping
it around until the following subtitle is decoded, and then utilizes
the following subtitle's pts as the end point of the previous one.
Signed-off-by: Jan Ekström <jan.ekstrom@24i.com>
Peeking into the muxing queue can improve the estimate of
the lowest timestamp needed for avoid_negative_ts in case
the lowest timestamp is in a packet other than the first packet
to be muxed.
This fixes tickets #4536 and #5784 as well as the output from
the matroska-avoid-negative-ts FATE-test.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
write_packet() has code to shift the packets timestamps
to make them nonnegative or even make them start at ts zero;
this code inspects every packet that is written and if a packet
with negative timestamp (whether this is dts or pts depends upon
another flag; basically: Matroska uses pts, everyone else dts)
is encountered, this is offset to make the timestamp zero.
All further packets will be offset accordingly (with the offset
converted according to the streams' timebases).
This is based around an assumption, namely that the timestamps
are indeed non-decreasing, so that the first packet with negative
timestamps is the first packet with timestamps. This assumption
is often fulfilled given that the default interleavement function
by default interleaves per dts; yet there are scenarios in which
it may not be fulfilled:
a) av_write_frame() instead of av_interleaved_write_frame() is used.
b) The audio_preload option is used.
c) When the timestamps that are made nonnegative/zero are pts
(i.e. with Matroska), because the packet with the smallest dts
is not necessarily the packet with the smallest pts.
d) Possibly with custom interleavement functions.
In these cases the relative sync of the first few packet(s) is offset
relative to the later packets. This contradicts the documentation
("When shifting is enabled, all output timestamps are shifted by
the same amount").
Therefore this commit changes this: As soon as the first packet
with valid timestamps is output, it is checked and recorded whether
the timestamps need to be shifted. Further packets are no longer
checked for needing to be offset; instead they are simply offset.
In the cases above this leads to packets with negative timestamps
(and the appropriate warnings) instead of desync. This will mostly
be fixed in the next commit.
This commit also factors handling the avoid_negative_ts stuff out
of write_packet() in order to be able to return immediately.
Tickets #4536 and #5784 as well as the matroska-avoid-negative-ts-test
are examples of c); as has been said, some timestamps are now negative,
yet the ref file update does not show it because ffmpeg.c sanitizes
the timestamps (-copyts disables it; ffprobe and mkvinfo also show
the original timestamps).
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
This tests the issue from tickets #4536, #5784;
the output of this test is currently broken.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Tests the parsing and writing of AVDOVIDecoderConfigurationRecord,
when it is present as a Dolby Vision configuration block addition mapping.
Signed-off-by: quietvoid <tcChlisop0@gmail.com>
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Up until now, the WebM variant of WebVTT subtitles has been handled
specially: It had its own function to write it, because the data
had to be reformatted before writing. But given that other codecs
also need reformatting, this is no good reason to also duplicate the
generic stuff for writing Block(Group)s.
This commit therefore uses an ordinary reformatting function for
this task; writing WebVTT subtitles now uses the generic code
and therefore automatically uses the least amount of bytes
for its BlockGroup length fields whereas the earlier code used
an overestimation for the length of the Duration element.
This is the reason for the changes to the webm-webvtt-remux FATE-test.
(This commit does not implement support for Matroska's way of muxing
WebVTT; it also does not add checks to ensure that WebM-style subtitles
don't get muxed in Matroska. But the function for reformatting gets a
webm prefix to indicate that this is for WebM.)
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
This commit uses the new EbmlWriter API to write the length fields
of the BlockGroup and its descendants that are themselves Master
elements (namely BlockAdditions and BlockMore) on the least amount of
bytes.
This fixes regressions introduced when the special code for writing
general subtitles was removed. Accordingly, the binsub-mksenc and
matroska-zero-length-block FATE-tests have now been reverted back
to their old state again; the advantages of this approach are evident
with the matroska-vp8-alpha-remux test which up until now wrote
all the length fields of all BlockGroups, BlockAdditions and BlockMore
on eight bytes.
Using the EbmlWriter API also allowed to improve locality in
mkv_write_block(): E.g. both DiscardPadding as well as the
BlockAdditional side-data are now directly used to add elements
to the writer whereas the earlier code had to first check
for whether a BlockGroup should be used and then check again
(after the place where a BlockGroup would be opened if one were
used) for whether there is DiscardPadding or BlockAdditional
side-data to write.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Once upon a time, mkv_write_block() only wrote a (Simple)Block,
not a BlockGroup which is needed for subtitles to convey
the duration. But with the introduction of support for writing
BlockAdditions and DiscardPadding (both of which require a BlockGroup),
mkv_write_block() can also open and close a BlockGroup of its own. This
naturally led to some code duplication which is removed in this commit.
This new code leads to one regression: It always uses eight bytes for
the BlockGroup's length field, whereas the earlier code usually used the
lowest amount of bytes needed. This will be fixed in a future commit.
This temporary regression is also the reason for changes to the
binsub-mksenc and matroska-zero-length-block fate tests.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Also check the (user-provided) tags for being overlong; the earlier
code had an implicit unchecked size_t->int conversion.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
To trigger this bug, use `paletteuse=dither=bayer:bayer_scale=0`; you will see
that adjacent pixel lines will use the same dither pattern, instead of being
shifted from each other by 32 units (0x20).
One way to demostrate the bug is:
$ convert -size 64x256 gradient:black-white -rotate 270 grad.png
$ echo 'P2 2 1 255 0 255' > bw.pnm
$ ffmpeg -i grad.png -filter_complex 'movie=bw.pnm,scale=256x1[bw]; [0:v][bw]paletteuse=dither=bayer:bayer_scale=0' gradbw.png
Previously: https://www.rm.cloudns.org/img/uploaded/0bd152c11b9cd99e5945115534b1bdde.png
Now: https://www.rm.cloudns.org/img/uploaded/89caaa5e36c38bc2c01755b30811f969.png
This was caused by passing inconsistent color vs (a,r,g,b) parameters to
color_get(), and NBITS being 5 meaning actually hitting the same cache node
does happen in this case, but ONLY if bayer_scale is zero.
The fix is passing the correct color value to color_get().
Also added a previous-failing FATE test; image comparison of the first frame:
Previously: https://www.rm.cloudns.org/img/uploaded/d0ff9db8d8a7d8a3b8b88bbe92bf5fed.png
Now: https://www.rm.cloudns.org/img/uploaded/a72389707e719b5cd1c58916a9e79ca8.png
(on this less synthetic test image, the bug basically causes noise from cache
hits vs misses)
Tested: FATE passes, which exercises this filter but at the default bayer_scale.
Reviewed-by: Paul B Mahol <onemda@gmail.com>
This is similar to the faststart option of the mov muxer, yet
in contrast to it it works together with reserve_index_space
(the equivalent to reserved_moov_size): If the reserved space
does not suffice, the data is shifted; if not, the Cues are
written at the front without shifting the data.
Several tests that cover (not only) this have been added.
Implements #7017.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
It returns a pointer inside the fifo's buffer, which cannot be safely
used without accessing AVFifoBuffer internals. It is easier and safer to
use av_fifo_generic_peek_at().
mvhd and tkhd present the post-editlist duration, while mdhd should
have the pre-editlist duration. Regression since c2424b1f3.
Signed-off-by: Martin Storsjö <martin@martin.st>
All the AMRWB samples are in a mov container.
Also use FATE_SAMPLES_FFMPEG instead of FATE_SAMPLES_AVCONV.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
- No longer mixes u8 and u16 component accesses (this was UB)
- De-duplicated 8->16 conversion
- De-duplicated component -> plane+offset conversion
- De-duplicated planar + packed RGB
- No longer calls ff_fill_rgba_map
- Removed redundant comp_mask data member
- RGB0 and related formats no longer write an alpha value to the 0 byte
- Non-planar YA formats now work correctly
- High-bit-depth semi-planar YUV now works correctly
And expose the parsed values as frame side data. Update FATE results to
match.
It's worth documenting that this relies on the dovi configuration record
being present on the first AVPacket fed to the decoder, which in
practice is the case if if the API user has called something like
av_format_inject_global_side_data, which is unfortunately not the
default.
This commit is not the time and place to change that behavior, though.
Signed-off-by: Niklas Haas <git@haasn.dev>
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
To avoid the ref for this growing to a very large size when attaching
the parsed RPU side data. Since this sample does not have any dynamic
metadata, two frames will serve just as well as 100.
Signed-off-by: Niklas Haas <git@haasn.dev>
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
The values for the essence element type were updated in the spec
from 0x05/0x06 (ST2019-4 2008) to 0x0C/0x0D (ST2019-4 2009).
Fixes ticket #6380.
Thanks-to: Philip de Nier <philip.denier@bbc.co.uk>
Thanks-to: Matthieu Bouron <matthieu.bouron@gmail.com>
Reviewed-by: Matthieu Bouron <matthieu.bouron@gmail.com>
Reviewed-by: Tomas Härdin <tjoppen@acc.umu.se>
Signed-off-by: Nicolas Gaullier <nicolas.gaullier@cji.paris>
Signed-off-by: Marton Balint <cus@passwd.hu>
Adds support for concat demuxer to copy the side data information
from the input file to the resulting file. It will behave like the
metadata copy, where the metadata of the first file is kept in the
the output file.
Extract the current code that already performs the stream side_data
copy into a separate method and reuse the method in the concat demuxer.
Signed-off-by: Gerard Sole <g.sole.ca@gmail.com>
They test libavfilter internal API, so they should be libavfilter
test programs (which implies: linked statically to libavfilter
to access internal APIs and linked normally (statically or dynamically
depending upon the build configuration) against all the other libs).
Right now, they are always linked statically against all libs,
which is a significant size waste compared to shared libs as all
of libavcodec has been pulled in despite not being really used.
This also leads to linking failures on systems for which av_export_avutil
is intended: libavcodec does not expect to be linked statically
against the library providing avpriv_(cga|vga16)_font in this case.
This is fixed by this commit.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
{kind=link}
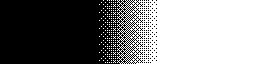{kind=link}
{kind=link}
{kind=link}