Ferret
![]()
![]()


![]()
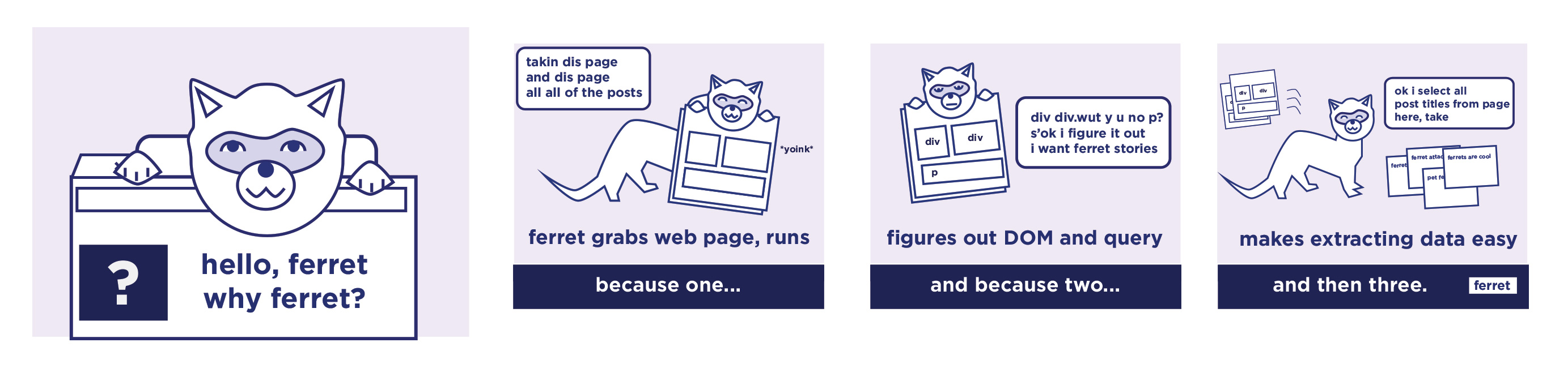
What is it?
ferret is a web scraping system. It aims to simplify data extraction from the web for UI testing, machine learning, analytics and more.
ferret allows users to focus on the data. It abstracts away the technical details and complexity of underlying technologies using its own declarative language.
It is extremely portable, extensible, and fast.
Read the introductory blog post about Ferret here!
Features
- Declarative language
- Support of both static and dynamic web pages
- Embeddable
- Extensible
Show me some code
The following example demonstrates the use of dynamic pages.
We load the main Google Search page, type a search criteria into the input box, and then click the search button.
The click action triggers a redirect, so we wait until the the page we were redirected to finishes loading.
Once the results page is loaded, we iterate over all elements in the search results and assign output to a variable.
LET google = DOCUMENT("https://www.google.com/", {
driver: "cdp",
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36"
})
HOVER(google, 'input[name="q"]')
WAIT(RAND(100))
INPUT(google, 'input[name="q"]', @criteria, 30)
WAIT(RAND(100))
WAIT_ELEMENT(google, '.UUbT9')
WAIT(RAND(100))
CLICK(google, 'input[name="btnK"]')
WAIT_NAVIGATION(google)
FOR result IN ELEMENTS(google, '.g')
// filter out extra elements like videos and 'People also ask'
FILTER TRIM(result.attributes.class) == 'g'
RETURN {
title: INNER_TEXT(result, 'h3'),
description: INNER_TEXT(result, '.rc > div:nth-child(2) span'),
url: INNER_TEXT(result, 'cite')
}
You can find more examples here.
Motivation
Nowadays, data is everything and who owns data - owns the world.
I have worked on multiple data-driven projects where data was an essential part of a system, and I realized how repetitive it is to write scraping code.
Other scraping libraries require lots of boilerplate code and tend to encourage an imperative approach to extracting data.
After some time looking for a tool that would let me declare which data I needed (instead of imperatively instructing it how to extract it), I decided to build my own solution.
ferret project is an ambitious initiative trying to bring the universal platform for writing scrapers without the hassle of other scrapers.
Inspiration
FQL (Ferret Query Language) is meant to feel like writing a database query. It is heavily inspired by AQL (ArangoDB Query Language). But, due to the domain specifics, there are some differences in syntax and how things work.
Installation
Binary
You can download the latest binaries from here.
Source code
Production
- Go >=1.11
- Chrome or Docker
Development
- GNU Make
- ANTLR4 >=4.8
go get github.com/MontFerret/ferret
Environment
In order to use all Ferret features, you will need to have Chrome either installed locally or running in Docker. For ease of use, we recommend to running Chromium inside a Docker container. You can probably use most Chromium-based headless images, but we've put together an image that's ready to go:
docker pull montferret/chromium
docker run -d -p 9222:9222 montferret/chromium
If you'd rather see what's happening during query execution, just start launch Chrome from your host with the remote debugging port set:
chrome.exe --remote-debugging-port=9222
Quick start
Browserless mode
If you want to try out fql, you can get started without Chrome or a Chromium container.
Executing the ferret CLI without any options will open ferret in REPL mode.
ferret
ferret will run in REPL mode.
Welcome to Ferret REPL
Please use `exit` or `Ctrl-D` to exit this program.
>%
>LET doc = DOCUMENT('https://news.ycombinator.com/')
>FOR post IN ELEMENTS(doc, '.storylink')
>RETURN post.attributes.href
>%
Note: symbol % is used to start and end multi-line queries. You also can use the heredoc format.
If you want to execute a query stored in a file, just pass a file name:
ferret ./docs/examples/static-page.fql
cat ./docs/examples/static-page.fql | ferret
ferret < ./docs/examples/static-page.fql
Browser mode
By default, ferret loads HTML pages directly via HTTP protocol, because it's faster.
But, nowadays, more and more websites are rendered with JavaScript, and this 'old school' approach does not really work.
For these dynamic websites, you may fetch documents using Chrome or Chromium via Chrome DevTools protocol (aka CDP).
First, you need to make sure that you launched Chrome with remote-debugging-port=9222 flag (see "Environment" in this README for instructions on setting this up).
Second, you need to pass the address to ferret CLI.
ferret --cdp http://127.0.0.1:9222
NOTE: By default, ferret will try to use this local address as a default one.
You only need to explicitly pass the parameter if you are using a different port number or remote address.
Alternatively, you can tell CLI to launch Chrome for you.
ferret --cdp-launch
Once ferret knows how to communicate with Chrome, you can use the function DOCUMENT(url, isDynamic), setting isDynamic to {driver: "cdp"} for dynamic pages:
Welcome to Ferret REPL
Please use `exit` or `Ctrl-D` to exit this program.
>%
>LET doc = DOCUMENT('https://soundcloud.com/charts/top', { driver: "cdp" })
>WAIT_ELEMENT(doc, '.chartTrack__details', 5000)
>LET tracks = ELEMENTS(doc, '.chartTrack__details')
>FOR track IN tracks
> LET username = ELEMENT(track, '.chartTrack__username')
> LET title = ELEMENT(track, '.chartTrack__title')
> RETURN {
> artist: username.innerText,
> track: title.innerText
> }
>%
Welcome to Ferret REPL
Please use `exit` or `Ctrl-D` to exit this program.
>%
>LET doc = DOCUMENT("https://github.com/", { driver: "cdp" })
>LET btn = ELEMENT(doc, ".HeaderMenu a")
>CLICK(btn)
>WAIT_NAVIGATION(doc)
>WAIT_ELEMENT(doc, '.IconNav')
>FOR el IN ELEMENTS(doc, '.IconNav a')
> RETURN TRIM(el.innerText)
>%
Embedded mode
ferret is a very modular system.
It can be embedded into your Go application in only a few lines of code.
Here is an example of a short Go application that defines an fql query, compiles it, executes it, then returns the results.
package main
import (
"context"
"encoding/json"
"fmt"
"os"
"github.com/MontFerret/ferret/pkg/compiler"
"github.com/MontFerret/ferret/pkg/drivers"
"github.com/MontFerret/ferret/pkg/drivers/cdp"
"github.com/MontFerret/ferret/pkg/drivers/http"
)
type Topic struct {
Name string `json:"name"`
Description string `json:"description"`
URL string `json:"url"`
}
func main() {
topics, err := getTopTenTrendingTopics()
if err != nil {
fmt.Println(err)
os.Exit(1)
}
for _, topic := range topics {
fmt.Println(fmt.Sprintf("%s: %s %s", topic.Name, topic.Description, topic.URL))
}
}
func getTopTenTrendingTopics() ([]*Topic, error) {
query := `
LET doc = DOCUMENT("https://github.com/topics")
FOR el IN ELEMENTS(doc, ".py-4.border-bottom")
LIMIT 10
LET url = ELEMENT(el, "a")
LET name = ELEMENT(el, ".f3")
LET description = ELEMENT(el, ".f5")
RETURN {
name: TRIM(name.innerText),
description: TRIM(description.innerText),
url: "https://github.com" + url.attributes.href
}
`
comp := compiler.New()
program, err := comp.Compile(query)
if err != nil {
return nil, err
}
// create a root context
ctx := context.Background()
// enable HTML drivers
// by default, Ferret Runtime does not know about any HTML drivers
// all HTML manipulations are done via functions from standard library
// that assume that at least one driver is available
ctx = drivers.WithContext(ctx, cdp.NewDriver())
ctx = drivers.WithContext(ctx, http.NewDriver(), drivers.AsDefault())
out, err := program.Run(ctx)
if err != nil {
return nil, err
}
res := make([]*Topic, 0, 10)
err = json.Unmarshal(out, &res)
if err != nil {
return nil, err
}
return res, nil
}
Extras
Extensibility
With ferret's modular system, you can also extend its standard library.
In this example, we define a transform function in Go, then register that function with ferret, making it available for use in fql queries.
package main
import (
"context"
"encoding/json"
"fmt"
"os"
"strings"
"github.com/MontFerret/ferret/pkg/compiler"
"github.com/MontFerret/ferret/pkg/runtime/core"
"github.com/MontFerret/ferret/pkg/runtime/values"
)
func main() {
strs, err := getStrings()
if err != nil {
fmt.Println(err)
os.Exit(1)
}
for _, str := range strs {
fmt.Println(str)
}
}
func getStrings() ([]string, error) {
// function implements is a type of a function that ferret supports as a runtime function
transform := func(ctx context.Context, args ...core.Value) (core.Value, error) {
// it's just a helper function which helps to validate a number of passed args
err := core.ValidateArgs(args, 1, 1)
if err != nil {
// it's recommended to return built-in None type, instead of nil
return values.None, err
}
// this is another helper functions allowing to do type validation
err = core.ValidateType(args[0], core.StringType)
if err != nil {
return values.None, err
}
// cast to built-in string type
str := args[0].(values.String)
return values.NewString(strings.ToUpper(str.String() + "_ferret")), nil
}
query := `
FOR el IN ["foo", "bar", "qaz"]
// conventionally all functions are registered in upper case
RETURN TRANSFORM(el)
`
comp := compiler.New()
if err := comp.RegisterFunction("transform", transform); err != nil {
return nil, err
}
program, err := comp.Compile(query)
if err != nil {
return nil, err
}
out, err := program.Run(context.Background())
if err != nil {
return nil, err
}
res := make([]string, 0, 3)
err = json.Unmarshal(out, &res)
if err != nil {
return nil, err
}
return res, nil
}
You can completely turn off the ferret standard library, as follows:
comp := compiler.New(compiler.WithoutStdlib())
After disabling stdlib, you can register your own implementation of functions from standard library.
If you only need a subset of the stdlib functions, you can only have those enabled by disabling the entire stdlib, then registering the individual packages that are needed:
package main
import (
"github.com/MontFerret/ferret/pkg/compiler"
"github.com/MontFerret/ferret/pkg/stdlib/strings"
)
func main() {
comp := compiler.New(compiler.WithoutStdlib())
comp.RegisterFunctions(strings.NewLib())
}
Proxy
By default, ferret does not attempt to use a proxy. This is due to an inability to CDP-compatible browsers to use an arbitrary proxy. If you need to use a proxy, it should be defined while launching the browser.
However, if you are querying static pages, you can define a proxy while launching ``ferret``` from the CLI or from embedded applications.
CLI example
ferret --proxy=http://localhost:8888 my-query.fql
Embedded example
package main
import (
"context"
"encoding/json"
"fmt"
"os"
"github.com/MontFerret/ferret/pkg/compiler"
"github.com/MontFerret/ferret/pkg/drivers"
"github.com/MontFerret/ferret/pkg/drivers/http"
)
func run(q string) ([]byte, error) {
proxy := "http://localhost:8888"
comp := compiler.New()
program := comp.MustCompile(q)
// create a root context
ctx := context.Background()
// we inform the driver what proxy to use
ctx = drivers.WithContext(ctx, http.NewDriver(http.WithProxy(proxy)), drivers.AsDefault())
return program.Run(ctx)
}
Cookies
Get, Set, Delete
For more precise work, you can set/get/delete cookies manually before and after loading the page:
LET doc = DOCUMENT("https://www.google.com", {
driver: "cdp",
cookies: [
{
name: "foo",
value: "bar"
}
]
})
COOKIE_SET(doc, { name: "baz", value: "qaz"}, { name: "daz", value: "gag" })
COOKIE_DEL(doc, "foo")
LET c = COOKIE_GET(doc, "baz")
FOR cookie IN doc.cookies
RETURN cookie.name
Access previously-set cookies (non-incognito mode)
By default, CDP driver execute each query in an incognito mode in order to avoid collisions from cookies persisted by previous queries.
However, sometimes you might want access to persisted cookies (e.g. to avoid re-authenticating with a site).
In order to do that, we need to configure the driver to execute all queries in non-incognito tabs.
Here is how to do that:
CLI example
ferret --cdp-keep-cookies my-query.fql
Embedded example
package main
import (
"context"
"encoding/json"
"fmt"
"os"
"github.com/MontFerret/ferret/pkg/compiler"
"github.com/MontFerret/ferret/pkg/drivers"
"github.com/MontFerret/ferret/pkg/drivers/cdp"
)
func run(q string) ([]byte, error) {
comp := compiler.New()
program := comp.MustCompile(q)
// create a root context
ctx := context.Background()
// we inform the driver to keep cookies between queries
ctx = drivers.WithContext(
ctx,
cdp.NewDriver(cdp.WithKeepCookies()),
drivers.AsDefault(),
)
return program.Run(ctx)
}
Query
LET doc = DOCUMENT("https://www.google.com", {
driver: "cdp",
keepCookies: true
})
File System
ferret can also read and write to the file system.
Write example
USE IO::FS
LET favicon = DOWNLOAD("https://www.google.com/favicon.ico")
RETURN WRITE("google.favicon.ico", favicon)
Read example
USE IO::FS
LET urls_data = READ("urls.json")
LET urls = JSON_PARSE(urls_data)
FOR url IN urls
RETURN DOCUMENT(url)
References
Further documentation is available at our website