mirror of
https://github.com/laurent22/joplin.git
synced 2024-12-24 10:27:10 +02:00
32 lines
3.1 KiB
Markdown
32 lines
3.1 KiB
Markdown
# Optical Character Recognition (OCR)
|
|
|
|
Optical Character Recognition (OCR) involves transforming an image containing text into a format that a machine can interpret. When you scan a text document, the computer stores it as an image file, preventing direct text editing or searching. OCR allows for the conversion of the image into text.
|
|
|
|
## Enabling OCR
|
|
|
|
You can enable OCR from the [Configuration screen](https://github.com/laurent22/joplin/blob/dev/readme/apps/config_screen.md), under the "General" section. Once you do so, Joplin is going to scan your images and PDF files to extract text data from it. That data will not be visible but will be associated with those files.
|
|
|
|
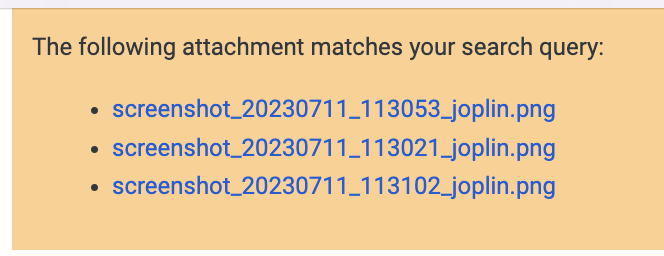
Then, when you search, the application will be able to tell you what notes but also what attachments match the query. In this case, a banner will be displayed at the top of the note that contains the attachment(s):
|
|
|
|
|
|
|
|
Searching in OCR text is enabled on the desktop and mobile app. Scanning documents however is only available on the desktop app since this is a relatively resource-intensive process. The mobile app will have access to that OCR data via sync.
|
|
|
|
For now OCR is reliable when scanning printed text, PDFs in particular, or images where the text is clear such as screenshots. We do not currently support handwritten text, and text on photos may or may not be recognized depending on how clear it is.
|
|
|
|
## Initial processing
|
|
|
|
As mentioned above processing images and PDF may be resource intensive, especially if you have a lot of attachments. So the first time you enable the feature don't be surprised if Joplin CPU usage is higher than usual. Once the initial scan of all your attachments is done, this will go back to normal. Late,r whenever you attach a file it will be scanned quickly in a way that's not noticeable.
|
|
|
|
## Offline first
|
|
|
|
As always, Joplin is offline first which means OCR too happens offline without the need for an internet connection and, more importantly, without the need to upload your private data to a third party cloud. The drawback is the aforementioned initial use of your computer's resources, but we believe this is worth it to enable full offline support.
|
|
|
|
## Pluggable system
|
|
|
|
OCR is a technology that evolves rapidly especially with the recent advances in AI and large language model (LLM) in particular. As such Joplin OCR is designed to be pluggable. We will monitor the existing open source OCR technologies and may switch to a different one if it makes sense, or provide support for multiple ones.
|
|
|
|
Additionally in some cases it may make sense to use a cloud-based solution, or simply connect to your self-hosted or intranet-based server for OCR. The current system will allow this by writing specific drivers for these services.
|
|
|
|
This pluggable interface is present in the software but not currently exposed. We will do so depending on feedback we receive and potential use cases. If you have any specific use case in mind or notice any issue with the current OCR system feel free to let us know [on the forum](https://discourse.joplinapp.org/).
|