6.3 KiB
Synchronous Scroll
Since Joplin 2.6, the synchronous scroll feature (Sync Scroll) for two-pane Markdown Editor is introduced. This document describes its detail.
Motivation
Joplin has two types of editors, two-pane Markdown Editor and WYSIWYG Editor. Two-pane Markdown Editor consists of an editor pane displaying a Markdown text (Editor) and a viewer pane displaying the rendered Markdown in HTML (Viewer). Both panes have independent scroll bars, and they were linked and controlled by single scroll position expressed as a relative percentage.
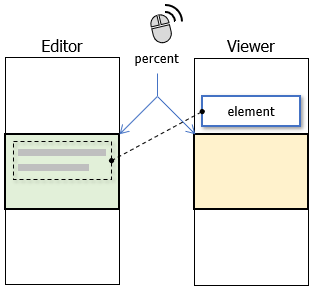
Since the height of a Markdown text line is not always proportional to the height of the corresponding HTML element, displayed contents in Editor and Viewer are often inconsistent.
To keep the consistency of their displayed contents, both scroll bars needed to be controlled separatedly and synchronously.
Feature Specifications
-
Markdown Editor and Viewer scroll synchronously.
- If you scroll Editor, Viewer is scrolled synchronously. The DOM elements corresponding to Markdown lines you are looking at in Editor's viewport are located in Viewer's viewport as possible.
- The same applies in reverse. (Viewer -> Editor)
- During and after any operations, the consistency of scroll positions between Editor and Viewer is kept as possible.
-
Performance requirement: Since scrolling is a basic GUI operation, its overhead should be minimized.
Design
Abstraction View
The following figure shows the abstraction view of Sync Scroll. To manage scroll positions, the percent of the line number of a Markdown text data ("percent" in the figure) is used. To handle GUI components and events, "percent" is translated from/to "ePercent" for Editor using translation function E2L() / L2E(). The same is true for Viewer.
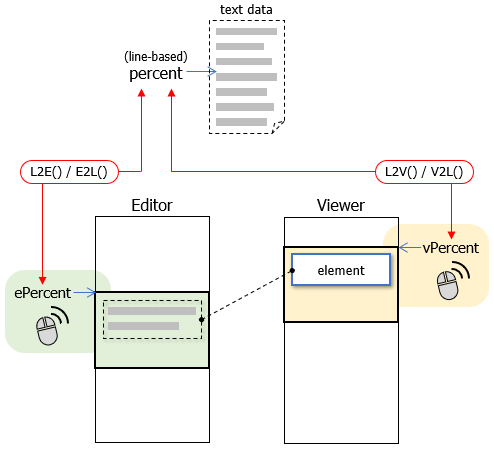
The reasons why "ePercent" is not directly translated from "vPercent" and vice versa are:
- Line-based "percent" is good for maintaining, because it is GUI-independent. Both "ePercent" and "vPercent" depend on GUI components and are affected by many factors such as image loading, window resizing, pane hiding/showing.
- Direct conversion between Editor and Viewer needs both Editor and Viewer are present. If one of them is hidden, the information needed for conversion cannot be acquired.
- Editor and Viewer run in different processes, so separation between them makes things simpler and reduces timing issues.
Components and Data Interactions
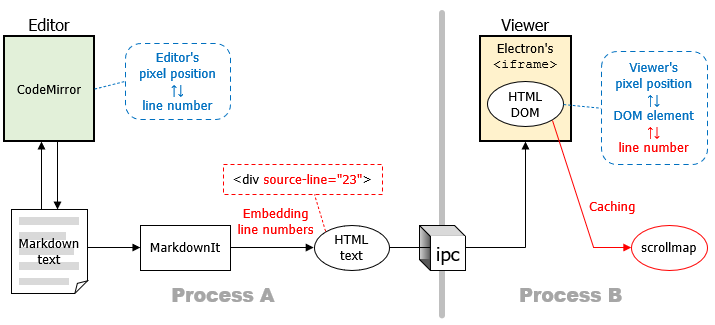
The next figure shows the components and data interactions related to Markdown Editor and Sync Scroll.
First, underlying Markdown Editor is explained. Editor is implemented using CodeMirror, and it provides the translation capability between line numbers of Markdown text and their pixel positions in Editor. A Markdown text being edited in Editor is converted to an HTML text using MarkdownIt, and it is rendered by Viewer, which is implemented using Electron's <iframe>. Editor and Viewer run in different processes, so an HTML text is sent through inter-process communication (ipc). Viewer has the rendered HTML as a DOM and provides the translation capability between DOM elements and their pixel positions in Viewer.
New additions for Sync Scroll are shown in the figure as red portions. Since a DOM don't know the mapping between lines and elements, mapping information is embedded into an HTML tag as an additional attribute source-line using MarkdownIt. By using the attributes, the translation capability between line numbers and their pixel positions in Viewer can be provided. The information required for the translation is cached in scrollmap described later.
Scroll Position Translation
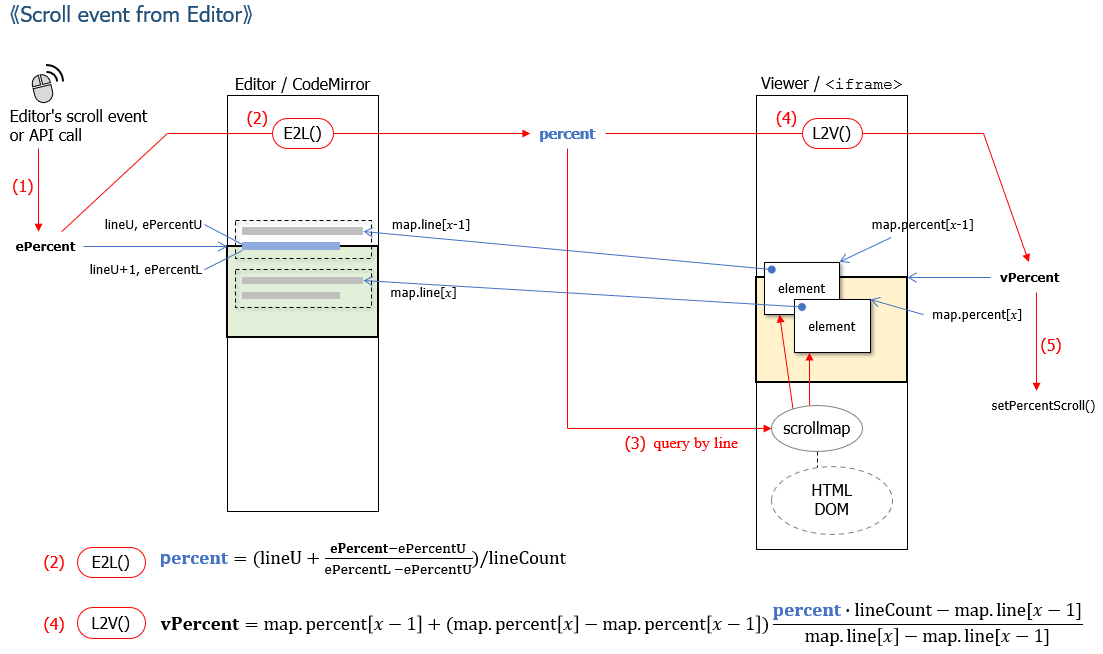
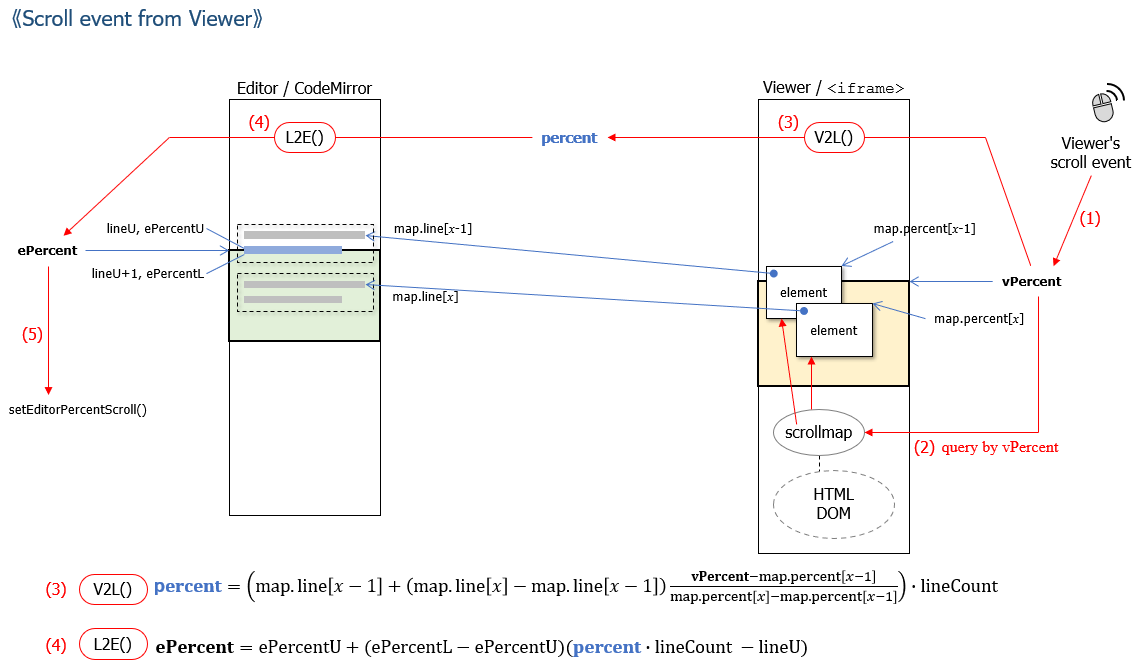
The next figure explains the procedure of the translation from "ePercent" to "percent" and the translation from "percent" to "vPercent". For the translation function E2L(), information acquired from CodeMirror used in Editor is used. For the translation function L2V(), information acquired from HTML DOM which is cached in scrollmap is used.
To estimate precise positions between lines/elements, linear interpolation algorithm is used as shown in the figure.
Similarly, the next figure explains the procedure of the translation from "vPercent" to "percent" and the translation from "percent" to "ePercent".
Caching Translation Map
The translation from "vPercent" to "percent" is a costly task, because it involves scanning the whole DOM. To keep scrolling as light as possible, the information required for the translation is packed into a translation map named scrollmap and is cached for further reuses until outdated.
Since scrollmap is already sorted, the binary search algorithm can be employed for querying lines or positions. It's faster than the linear search, and a query needed for one scrolling event/action is very light.
For correct operation, the map should be discarded, when it becomes outdated, such as when a note is switched, when a note is edited, and when the window is resized. Simultaneously, the frequency of recreations should be minimal for users' comfort.
Implementation Details
The implementation details are out of the scope this document and described in the following pull requests.