This will allow to avoid the temporary buffer and memcpys
when repacketing annex B to mp4-style H.264/H.265 without
searching twice for start codes.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Matroska does not have different profiles that allow or disallow
in-band extradata, so one can just use the ordinary H.264 function
for H.265, too. (Both use ff_avc_parse_nal_units() internally anyway.)
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
This avoids allocations+copies in all cases, not only those
in which the desired OBUs are contiguous in the input buffer.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Document that it can be used with a NULL AVIOContext to
get the output size in a first pass.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
WavPack's blocks use a length field, so that parsing them is fast.
Therefore it makes sense to parse the block twice, once to get
the length of the output packet and once to write the actual data
instead of writing the data into a temporary buffer in a single pass.
This speeds up muxing from 1597092 to 761850 Decicycles per
write_packet call for a 2000kb/s stereo WavPack file muxed to /dev/null
with writing CRC-32 disabled.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Matroska uses variable-length elements and in order not to waste
bytes on length fields, the length of the data to write needs to
be known before writing the length field. Annex B H.264/5 and
WavPack need to be reformatted to know this length and this
currently involves writing the data into temporary buffers;
AV1 sometimes suffers from this as well.
This commit aims to solve this by adding a callback that is called
twice per packet: Once to get the size and once to actually write
the data. In case of WavPack and AV1 (where parsing is cheap due
to length fields) both calls will just parse the data with only
the second function writing anything. For H.264/5, the position
of the NALUs will need to be stored to be written lateron.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Avoids the surprise of using pb for the main AVIOContext
at the beginning and end of mkv_write_header() and for
for the dynamic buffer opened for the Info element
in the middle of mkv_write_header().
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Using start/end_ebml_master() to write an EBML Master element
uses seeks under the hood. This does not work if the output is
unseekable with the AVIOContext's buffer being very small
(the size of the currently written Matroska EBML header is 40)
or with the AVIOContext being in direct mode, because then
this seek can't be performed in the AVIOContext's buffer.
So using an approach that does not rely on seeking at all
is preferable; this is achieved by switching to EbmlWriter.
Also factor writing the EBML header out into a function of its own.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Also check the (user-provided) tags for being overlong; the earlier
code had an implicit unchecked size_t->int conversion.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
This muxer currently uses two ways to ensure that no bytes
are wasted by writing unnecessary long EBML length fields
for Master elements and the (Simple)Block element
(all the other elements are fine as one either already has
the right length or getting the actual length is easy
and necessary anyway):
Either use an upper bound that is good enough in case one
is available or write the data into a dynamic buffer first
to get the length; the former approach is impossible in
lots of cases, whereas the latter incurs allocations and
memcpying. It is therefore unfeasible to use the latter
for e.g. the attachments or the BlockGroups.
This patch adds a third alternative to complement the other two:
It consists of an EbmlWriter that one can add EBML elements to
that can be written later by calling ebml_writer_write();
the latter function first traverses the written elements recursively
and calculates the length of each element; then a second pass
is performed in which all the elements are written directly
(without any seeks).
This new API also performs checks for overlong elements;
this is in contrast to put_ebml_string() which simply performs
a size_t->int conversion even for strings originating from the user.
The new API is designed to have very low overhead: It uses
stack arrays and performs no allocations; this also comes
at a price: Right now, it can only be used in contexts in which
there is a compile-time upper bound for the number of elements.
It is also incompatible with storing the offset of an element
in order to update this field later. Furthermore, it puts
the onus of memory management (i.e. ensuring that pointers stay valid)
on the user.
These restrictions might be overcome in the future.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
This would happen in case non-WebVTT-subtitles had BlockAdditional
or DiscardPadding side-data. Given that these are not accounted for
in the length of the outer BlockGroup (which is a quite sharp upper
bound) it is possible for the outer BlockGroup to use an insufficient
number of bytes which leads to an assert in end_ebml_master().
Fix this by not opening a second BlockGroup inside an already opened
BlockGroup.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
add a dictionary that maps "src_url" -> "expiry;dst_url", the dictionary
is checked before issuing an http request, and updated after getting a
3xx redirect response.
the cache expiry is determined according to the following (in desc
priority) -
1. Expires header
2. Cache-Control containing no-cache/no-store (disables caching)
3. Cache-Control s-maxage/max-age
4. Http codes 301/308 are cached indefinitely, other codes are not
cached
The SDK may insert picture timing SEI for hevc and the code to set mfx
parameter has been added in qsvenc, however the corresponding option is
missing in the hevc option array
Reviewed-by: Limin Wang <lance.lmwang@gmail.com>
Signed-off-by: Haihao Xiang <haihao.xiang@intel.com>
This can fill VAProcPipelineParameterBuffer correctly and make the
pipeline works.
Reviewed-by: Soft Works <softworkz@hotmail.com>
Signed-off-by: Fei Wang <fei.w.wang@intel.com>
Signed-off-by: Haihao Xiang <haihao.xiang@intel.com>
Overlay one video on the top of another.
It takes two inputs and has one output. The first input is the "main" video on
which the second input is overlaid. This filter requires same memory layout for
all the inputs.
An example command to use this filter to overlay overlay.mp4 at the top-left
corner of the main.mp4:
ffmpeg -init_hw_device vaapi=foo:/dev/dri/renderD128 \
-hwaccel vaapi -hwaccel_device foo -hwaccel_output_format vaapi -c:v h264 -i main.mp4 \
-hwaccel vaapi -hwaccel_device foo -hwaccel_output_format vaapi -c:v h264 -i overlay.mp4 \
-filter_complex "[0:v][1:v]overlay_vaapi=0:0:100💯0.5[t1]" \
-map "[t1]" -an -c:v h264_vaapi -y out_vaapi.mp4
Signed-off-by: U. Artie Eoff <ullysses.a.eoff@intel.com>
Signed-off-by: Xinpeng Sun <xinpeng.sun@intel.com>
Signed-off-by: Zachary Zhou <zachary.zhou@intel.com>
Signed-off-by: Fei Wang <fei.w.wang@intel.com>
Signed-off-by: Haihao Xiang <haihao.xiang@intel.com>
To trigger this bug, use `paletteuse=dither=bayer:bayer_scale=0`; you will see
that adjacent pixel lines will use the same dither pattern, instead of being
shifted from each other by 32 units (0x20).
One way to demostrate the bug is:
$ convert -size 64x256 gradient:black-white -rotate 270 grad.png
$ echo 'P2 2 1 255 0 255' > bw.pnm
$ ffmpeg -i grad.png -filter_complex 'movie=bw.pnm,scale=256x1[bw]; [0:v][bw]paletteuse=dither=bayer:bayer_scale=0' gradbw.png
Previously: https://www.rm.cloudns.org/img/uploaded/0bd152c11b9cd99e5945115534b1bdde.png
Now: https://www.rm.cloudns.org/img/uploaded/89caaa5e36c38bc2c01755b30811f969.png
This was caused by passing inconsistent color vs (a,r,g,b) parameters to
color_get(), and NBITS being 5 meaning actually hitting the same cache node
does happen in this case, but ONLY if bayer_scale is zero.
The fix is passing the correct color value to color_get().
Also added a previous-failing FATE test; image comparison of the first frame:
Previously: https://www.rm.cloudns.org/img/uploaded/d0ff9db8d8a7d8a3b8b88bbe92bf5fed.png
Now: https://www.rm.cloudns.org/img/uploaded/a72389707e719b5cd1c58916a9e79ca8.png
(on this less synthetic test image, the bug basically causes noise from cache
hits vs misses)
Tested: FATE passes, which exercises this filter but at the default bayer_scale.
Reviewed-by: Paul B Mahol <onemda@gmail.com>
This resulted in a dimmed tonemapping due to bad resulting luma
calculation.
Found by: Derek Buitenhuis
Signed-off-by: Vittorio Giovara <vittorio.giovara@gmail.com>
For high/main profile, user can choose to use cavlc by specify "-coder cavlc",
for default, it'll will use cabac, if it's baseline, we'll use cavlc by specs anyway.
ffmpeg -y -f lavfi -i testsrc -c:v libopenh264 -profile:v main -coder cavlc -frames:v 1 -bsf trace_headers -f null -
before the patch:
entropy_coding_mode_flag 0 = 1
after the patch:
entropy_coding_mode_flag 0 = 0
Reviewed-by: Martin Storsjö <martin@martin.st>
Signed-off-by: Limin Wang <lance.lmwang@gmail.com>
due to the limitations set in d3a7bdd4ac,
you weren't able to use main profile with OpenH264 1.8, or high profile
with older versions
Reviewed-by: Martin Storsjö <martin@martin.st>
Signed-off-by: Limin Wang <lance.lmwang@gmail.com>
This is similar to the faststart option of the mov muxer, yet
in contrast to it it works together with reserve_index_space
(the equivalent to reserved_moov_size): If the reserved space
does not suffice, the data is shifted; if not, the Cues are
written at the front without shifting the data.
Several tests that cover (not only) this have been added.
Implements #7017.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Fixes: division by zero
Fixes: integer overflow
Fixes: 43347/clusterfuzz-testcase-minimized-ffmpeg_dem_V210X_fuzzer-5846911637127168
Found-by: continuous fuzzing process https://github.com/google/oss-fuzz/tree/master/projects/ffmpeg
Reviewed-by: lance.lmwang@gmail.com
Reviewed-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
Signed-off-by: Michael Niedermayer <michael@niedermayer.cc>
The current size is AV_NUM_DATA_POINTERS (i.e. eight).
This number is chosen in order to minimize the amount of allocations
for AVFrame.extended_(data|buf) for audio; it is meaningless
for video for which four is sufficient. So decrease this array
in order to minimize what is copied in ff_mpeg_ref_picture()
and at the places that copy a whole MpegEncContext.
Also do the same for snowenc.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
These messages belong together, yet they can be torn apart
if some other call to av_log() happens between them.
Reviewed-by: Michael Niedermayer <michael@niedermayer.cc>
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
RV40, SVQ3 and VP7/VP8 are eight-bit only, so it makes no sense
to check for them in the codepath initializing > eight bit contexts.
Move the codec-specific code to a switch located after the eight-bit
init code where this is easily possible; and add checks to the macro
to enable the compiler to remove the remaining checks when initializing
bitdepths > 8 at compile-time.
Signed-off-by: Andreas Rheinhardt <andreas.rheinhardt@outlook.com>
qHD is 960x540 (q stands for quarter) and QHD is 2560x1440 (Q is quad).
use quadhd for QHD for abbreviation.
Fix ticket#9591
Signed-off-by: Limin Wang <lance.lmwang@gmail.com>
For DeinterlacingBob mode with rate=field, the frame number of output
should equal 2x input total since only intra deinterlace is used.
Currently for "backward_ref = 0, rate = field", extra_delay is
introduced. Due to the async without flush, frame number of output is
[expected_number - 2].
Specifically, if the input only has 1 frame, the output will be empty.
Add deint_vaapi_request_frame for deinterlace_vaapi, send NULL frame
to flush the queued frame.
For 1 frame input in Bob mode with rate=field,
before patch: 0 frame;
after patch: 2 frames;
ffmpeg -hwaccel vaapi -hwaccel_device /dev/dri/renderD128
-hwaccel_output_format vaapi -i input.h264 -an -vf
deinterlace_vaapi=mode=bob:rate=field -f null -
Tested-by: Mark Thompson <sw@jkqxz.net>
Reviewed-by: Mark Thompson <sw@jkqxz.net>
Signed-off-by: Linjie Fu <linjie.fu@intel.com>
Signed-off-by: Haihao Xiang <haihao.xiang@intel.com>
MSDK vc1 and av1 sometimes output frame into the same suface, but
ffmpeg-qsv assume the surface will be used only once, so it will
unref the frame when it receives the output surface. Now change
it to unref frame according to queue count.
Signed-off-by: Wenbin Chen <wenbin.chen@intel.com>
Signed-off-by: Haihao Xiang <haihao.xiang@intel.com>
{kind=link}
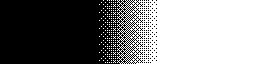{kind=link}
{kind=link}
{kind=link}